جوجل تكشف عن نموذج ذكاء اصطناعي لتوليد الفيديو
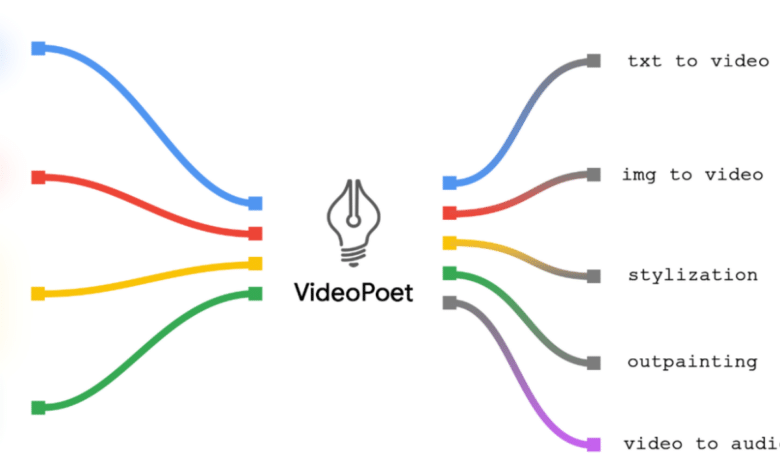
كشفت جوجل عن نموذجها اللغوي الكبير الجديد لتوليد الفيديو المسمى VideoPoet، وهو مصمم من أجل أداء مجموعة من المهام، ومنها تحويل النص إلى فيديو، وتحويل الصورة إلى فيديو، وتحويل الفيديو إلى صوت.
ويعالج تقديم VideoPoet التحدي المتمثل في توليد الحركات الكبيرة المتماسكة في مقاطع الفيديو، وهو قيد في تقنيات توليد الفيديو الحالية.
ويميز هذا النموذج الجديد نفسه من خلال إدماج القدرات المتعددة لتوليد الفيديو في إطار نموذجي لغوي كبير واحد، على النقيض من النهج المجزأ للنماذج الحالية.
ويستخدم النموذج طرقًا مختلفة، وهو مدرب باستخدام العديد من الرموز المميزة، مثل MAGVIT V2 للفيديو والصور، و SoundStream للصوت.
ويتيح ذلك لنموذج VideoPoet أداء مهام متنوعة، بدءًا من تحريك الصور وحتى تحرير مقاطع الفيديو وتصميمها استنادًا إلى مدخلات النص.
ويبرز VideoPoet بصفته تقدمًا كبيرًا في المشهد المتطور لتقنية توليد الفيديو بالذكاء الاصطناعي، إذ يميز نفسه عن النماذج الحالية، مثل Imagen Video و RunwayML و Stable Video Diffusion و Pika و Animate Anywhere، من خلال قدراته المحسنة في دقة النص وإثارة الحركة.
ويتفوق هذا النموذج الجديد على نظرائه من خلال اتباع المطالبات النصية بشكل دقيق وتوليد مقاطع فيديو بحركات جذابة.
ويتفوق نموذج جوجل الجديد في توليد المحتوى باستخدام الحد الأدنى من المدخلات، مثل رسالة نصية واحدة أو صورة واحدة، دون الحاجة إلى تدريب محدد على هذا المحتوى.
ويعرض VideoPoet درجة عالية من الدقة في ترجمة المطالبات النصية إلى فيديو، على عكس النماذج الأخرى التي قد تعاني مشكلة توليد الحركات الكبيرة المتماسكة، مما يعزز تجربة المستخدم.
وتواجه النماذج الأخرى في كثير من الأحيان تحديات في توليد الحركات الكبيرة المتماسكة الخالية من العيوب، في حين يُظهر نموذج جوجل الجديد تحسنًا ملحوظًا في هذا المجال، مما يؤدي إلى توليد مقاطع فيديو ديناميكية وسلسة.