باحثون يخترعون مكبر صوت «يكتم» الأشخاص المزعجين

طوّر باحثون مكبر صوت جديدًا يستطيع إعادة ترتيب ميكروفوناته السبعة «الذاتية النشر» لتقسيم الغرفة إلى ما يسمى بـ «مناطق الكلام»، مما يسمح له بتتبع الأصوات المختلفة وتعرفها، حتى أثناء تحرك الروبوتات.
ويقول الباحثون، الذين يقفون وراء الاختراع، إن التحديد الدقيق للمواقع هذا يسمح لهم ليس فقط بفصل المحادثات المتزامنة، بل أيضًا بكتم المناطق المزعجة «أو الأشخاص المزعجين» عند الطلب، وذلك لتطبيقات، مثل: مؤتمرات الفيديو في الاجتماعات.
وكما هو مفصل في دراسة حديثة عن الاختراع، نُشرت في مجلة (نيتشر كوميونيكيشنز) Nature Communications، فإن مكبر الصوت غير التقليدي يتكون مما يُعرف باسم سرب الروبوتات.
وتأتي الميكروفونات الذاتية النشر على هيئة روبوتات بحجم كشتبان تتواصل مع بعضها بعضًا، وتتحرك على عجلاتها الصغيرة إلى نقاط مختلفة بمفردها، ثم تعود إلى محطة الشحن عند الحاجة.
وقال (مالك عيتاني)، المؤلف الرئيسي للدراسة، في بيان: «للمرة الأولى، وباستخدام ما نسميه ’السرب الصوتي’ الآلي، أصبحنا قادرين على تتبع مواقع العديد من الأشخاص الذين يتحدثون في الغرفة وفصل كلامهم».
ويقول الباحثون إن الروبوتات النموذجية تستخدم للتنقل في بيئتها تقنية مشابهة لتقنية تحديد الموقع بالصدى العالي التردد.

وأضافوا أن التنقل أمر بالغ الأهمية، فمن خلال نشر الميكروفونات إلى أقصى حد ممكن، يمكن للشبكة العصبية التي تعالج البيانات إجراء حسابات دقيقة.
ومع ذلك، تقتصر الروبوتات في الوقت الحالي على التنقل على أسطح الطاولات، حيث إنها قادرة فقط على تحديد الموقع في مساحة ثنائية الأبعاد.
وأوضح المؤلف المشارك (توشاو تشين) في البيان: «لقد طورنا شبكات عصبية تستخدم هذه الإشارات المتأخرة زمنيًا لفصل ما يقوله كل شخص وتتبع مواقعه في المكان. لذلك يمكنك إجراء محادثتين بين أربعة أشخاص وعزل أي من الأصوات الأربعة وتحديد موقع كل صوت في الغرفة».
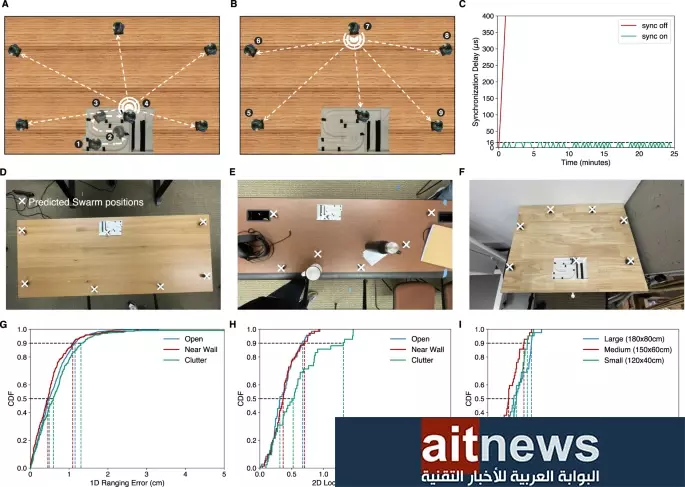
واختبر الباحثون سرب الروبوتات في أماكن، مثل: المكاتب، والمطابخ مع وجود عدد من الأشخاص الذين يتحدثون معًا يتراوح بين ثلاثة وخمسة أشخاص، وذلك دون أن يكون لدى النظام معرفة سابقة بالمواقع أو الأصوات.
وعلى الرغم من تلك العوائق، ظل الجهاز قادرًا على تحديد موقع الأصوات بنسبة 90 في المئة من الوقت، وذلك على مسافة 1.6 قدم من بعضها بعضًا. وفي الوقت نفسه، كان متوسط الخطأ أقل من ست بوصات في جميع السيناريوهات.
ومع ذلك، فإن سرعته لا ترقى إلى المطلوب. ففي المتوسط، يستغرق النظام 1.82 ثانية لمعالجة ما يعادل ثلاث ثوانٍ من الصوت، وهو ما قد يجعل العمل مع مؤتمرات الفيديو صعبًا بعض الشيء.
وفي الخطوة التالية، يريد الباحثون تطبيق تقنيات كتم الصوت والفصل هذه، في الفضاء المادي لحظيًا، وذلك باستخدام الميكروفونات الموضعية الخاصة بها للقيام بما تفعله سماعة الرأس المانعة للضوضاء في أذنيك، ولكن في غرفة بأكملها.